| |
TAMI
- a database and file management system for indigenous
use
Background:
We see the various projects emerging from IKRMNA arranged along a continuum with at one end, official archives with all their formal structure and metadata protocols, and at the other end a completely fluid file management and database system which bears with it no western assumptions about knowledge or the ecology, and which maximises the possibility for the user to creatively relate and annotate assemblages of resources for their own purposes. We call the system TAMI.
TAMI emerged as a concept from many sessions of working through sociotechnical issues to do work with Aboriginal knowledge and digital technology. For an account of the initial ideas to be formulated see "Computer databases and Aboriginal knowledge" on the publications page
TAMI, stands for Texts, Audio, Movies and Images. It is designed:
- to remain faithful to the principles and practices of indigenous knowledge production
- to be useful for people with little or no literacy skills
- for people who want to manage their own digital resources for perpetuating collective knowledge traditions
- assuming that by and large, at least for a good while, each database will be small, and users will generally have a good idea of what they are looking for in the database
- not to store large amounts of repatriated resources, but to make smaller amounts of valued resources easily enrichable for the purposes of collective memory making
- to be ontologically flat: as far as possible it encodes no assumptions about the nature of the world or the nature of knowledge, it is the user who encodes structure into the arrangements of resources and metadata, and these structures are flexible
- for the users to become the designers as they bring together resources, then group and order them, and create products (like DVDs and printouts). The ways in which truth claims are assembled and validated collectively within particular knowledge traditions, can be left fluid.
Some of the principles which underlie its structure are:
- one single screen enables search, upload and view. A workspace enables different objects to be viewed simultaneously, and arranged into folders
- users should be able to upload resources into the database by a simple drag-and-drop
- the only a priori ontological distinction at work in the database is the distinction between texts, audios, movies, and images. Apart from that there are no pre-existing categories (as there are in other database where metadata are sequestered into fields). This provides a certain ontological flatness so indigenous knowledge traditions are not pre-empted by western assumptions
- objects can be uploaded and searched without metadata. (metadata can be added at any time. Its purpose is to help text-based searching
- where there is metadata, there is a simple 1-1 relation between objects and metadata. Each object or assemblage has only one set of metadata and vice versa
- however, individuals can make assemblages, ‘folders’ of resources and give these folders metadata. So the database can hold collections of resources based on a theme and these folders can be labelled and found through text-search
- the natural way to find objects in the database is without a text-string search, that is, without a text driven FIND function. Texts, audio files, movies, and images can be searched by flicking through the full set of thumbnail resources
-
-
-
-
-
-
-
Text-based searching is guided by
a few principles:
- a glossariser produces a list of all the words which are already in the metadata (including file names)
- the list contains English and vernacular words
- the list is always visible on screen
- users can scroll and click words for both instigating a search, and adding metadata
- key-in and drop down menus work to reduce the glossary list to help search. (key in b and only b- words remain, key in a and only ba- words remain etc)
- metadata for objects displayed in the workspace can be altered at any time. The glossariser continuously updates the list of searchable words
- wherever possible existing conventions from software solutions which are already familiar to indigenous users are employed
|
|
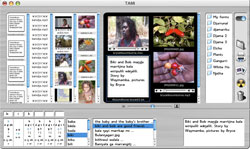
Click
here to view a Flash animation that illustrates some of the features of TAMI (2.5MB)
TAMI Documents
2nd draft of software
requirements for TAMI Download
1.2 MB pdf
1st draft of software
requirements for TAMI Download
1.7 MB pdf
Friendly text-based search
specification Download
116K pdf
Procedures for text-based
search documentation Download
76K pdf
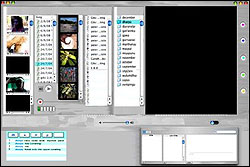
Beginnings of the TAMI interface
|
